I'm trying a new (to me) approach to learning programming languages: writing automated tests as a learning method. This surely isn't a new idea but I wanted to share my experience.
The concept is pretty straightforward:
- Discover how something works
- Write a test to illustrate your understanding (aim for concise examples)
- Add more tests as-needed to probe the boundaries of your understanding
These tests are effectively executable note-taking. You should try it.
Benefits
- As with traditional note-taking, the process of writing the tests help commit the concept to memory.
- The tests are there to reference in the future if I forget how something works.
- The tests' passing shows that my understanding is correct.
- I can update the tests when my understanding improves or I find a better approach.
- I can re-run the tests when a major version of the language is released to see what is deprecated.
You might worry that this effort is duplicating existing tests from the language itself. Right! But the purpose here is to solidify and exercise your understanding. (Do feel encouraged to consult the official tests afterwards as you can learn even more.)
An example
I needed to write a method in Elixir that could take an optional block as an argument (this is a common thing in Ruby/Rails). I did some digging and found the do: block approach (example). Next I wrote a couple tests in my local elixir_learning app to document my understanding:
describe "methods that take an optional block" do
defmodule OptionalBlock do
@moduledoc """
This works by specifying a method with and without the `do: block`
argument.
"""
def foo(arg1, arg2) do
[arg1, arg2]
end
def foo(arg1, arg2, do: block) do
[arg1, arg2, block]
end
end
test "without a block" do
assert OptionalBlock.foo("test", %{a: 1}) == ["test", %{a: 1}]
end
test "with a block" do
x = :example_result_of_block
result =
OptionalBlock.foo "test", %{a: 1} do
x
end
assert result == ["test", %{a: 1}, :example_result_of_block]
end
end
Now I understand the behavior. Whenever I forget how this works, I can come back to it for reference.
Further exploration
After writing the initial examples, I try to probe the edges of my understanding.
Looking at the code now, it isn't clear when block execution happens. Is it lazy (like in Ruby) or does it happen at function call time?
Let's write another test to find out:
# higher in the test file
import ExUnit.CaptureIO
test "time of block execution" do
defmodule UnusedBlock do
def foo(do: _block) do
# intentionally not using _block
end
end
assert capture_io(fn ->
IO.puts("Before")
UnusedBlock.foo do
IO.puts("Block")
end
IO.puts("After")
end) == "Before\nAfter\n"
end
Here we're making a guess at what the output might be. UnusedBlock.foo never uses block. If the do/end block is lazily-evaluated then we will only see the "Before" and "After" lines.
Running the test shows:
1) test methods that take an optional block time of block execution (OptionalBlockTest)
test/optional_block_test.exs:36
Assertion with == failed
code: assert capture_io(fn ->
IO.puts("Before")
UnusedBlock.foo() do
IO.puts("Block")
end
IO.puts("After")
end) == "Before\nAfter\n"
left: "Before\nBlock\nAfter\n"
right: "Before\nAfter\n"
stacktrace:
test/optional_block_test.exs:43: (test)
Our guess was incorrect: the "Block" line is present. This means the block is not lazily-evaluated. It is evaluated at the time the function is invoked.
This behavior is good to remember for the future and worth codifying in the test. We update our assertion to include the "Block" output line (we do expect it now) and update the test name to mention how the block is always invoked even if it goes unused.
Now I know a little more about how Elixir handles block arguments by default and I have executable notes to look back on.
If you want to learn more, Henrik Nyh has helpful background info and discusses using macros for lazy evaluation in his excellent Elixir block keywords article.
I've only been using this approach for a short while so I can't comment on the long-term benefits or downsides. I can say that I've really been enjoying the benefits mentioned above — particularly being able to experiment with my understanding in a reproducible way.
See also:
Over the holidays, I finally got around to reading Steve Losh's wonderful Learn Vimscript the Hard Way. I liked it so much that I bought a copy after reading it for free online.
In an effort to put what I've learned into practice, I'm going to walk through creating a simple plugin to evaluate Postgres queries and see the results immediately in Vim. I hope you'll follow along, and please feel free to substitute your database of choice.
Here's our plugin in action:
Background
Postgres is great. The CLI, psql, thankfully has \e to let you edit your queries in $EDITOR. You're probably fine just using \e (just remember to use the block comment style or your comments will be eaten by a grue).
But if I'm editing my queries in Vim anyway, why not also evaluate my queries from there? Sure, Vim is not an operating system (see :help design-not), but when we can see the results of our queries alongside our sql, we can create a tighter feedback loop. This integration opens up more possibilities for later (e.g. adding a mapping to describe the table under the cursor). It also gives us all of Vim for browsing the results (e.g. find, copy/paste, etc.).
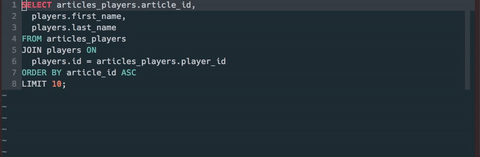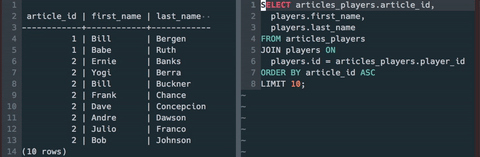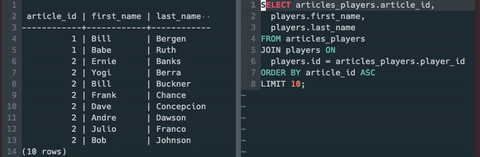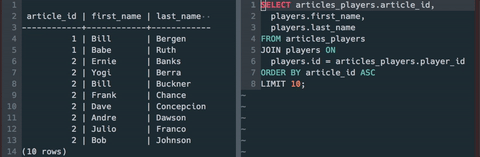
To get us started, here's a sample sql query to look at data from The Hall of Stats. It is an intentionally trivial example, but stick with me. Bring your own sql query to get data from one of your local databases if you're following along.
-- List first 10 players mentioned in articles
SELECT articles_players.article_id,
players.first_name,
players.last_name
FROM articles_players
JOIN players ON players.id = articles_players.player_id
ORDER BY article_id ASC
LIMIT 10;
It is easy enough to run a file with psql and see the results.
$ psql hos_development -f test.sql
article_id | first_name | last_name
------------+------------+------------
1 | Bill | Bergen
1 | Babe | Ruth
2 | Ernie | Banks
2 | Yogi | Berra
2 | Bill | Buckner
2 | Frank | Chance
2 | Dave | Concepcion
2 | Andre | Dawson
2 | Julio | Franco
2 | Bob | Johnson
(10 rows)
Getting started on the plugin
Our plugin will only have one file in it. In more complex plugins, you'll want to leverage autoloading, but we'll keep things simple here and keep all our code in one place.
In our plugin directory we have a ftplugin folder. In that folder, we'll create a file named sql.vim. This code will be automatically evaluated when a sql file is loaded.
$ mkdir -p sql_runner.vim/ftplugin
$ touch sql_runner.vim/ftplugin/sql.vim
Before we start coding away, we need to make Vim aware of our plugin. Add the following to your vimrc file (substituting the path to your plugin directory on disk):
set runtimepath+=,/some/absolute/path/to/sql_runner.vim
Perfect. Now in sql_runner.vim/ftplugin/sql.vim we set up the default mapping for our plugin.
nnoremap <buffer> <localleader>r :call RunSQLFile()<cr>
Note: There are good reasons to not provide default mappings in your plugin or to at least allow users to opt-out of your default mappings, but, again, we're keeping things simple.
We're using <localleader> for the mapping (check :help localleader for insight). If you haven't remapped <localleader> then it is still the default: \ (which makes this keybinding \r)
Let's start implementing RunSQLFile very naively at first:
function! RunSQLFile()
execute '!psql hos_development -f ' . expand('%')
endfunction
Save that and open up a sql file. Now press <localleader>r
Sure enough, this shows the output (until you hit enter to continue). Not a bad start, but we can already see a problem. We've hard-coded hos_development as the database name :( We're also not passing in a user or password to my psql command. That's OK on my machine since my user already has permissions on that database, but it isn't ideal to edit the plugin itself every time we want to change databases or specify permissions. Let's go ahead and make this more flexible.
function! RunSQLFile()
let l:cmd = g:sql_runner_cmd . ' -f ' . expand('%')
execute '!' . l:cmd
endfunction
This allows us to specify the global variable g:sql_runner_cmd in our vimrc (or define/redefine it on the fly). I'm adding let g:sql_runner_cmd = 'psql hos_development' to my vimrc (and :sourceing it).
Because our code is in a file in ftplugin, you should be able to reload the plugin after saving changes by editing your sql file again (:e). Give the command another try. The output should be the same (except that you won't see the command itself echoed back).
Now that our plugin is a little more flexible, what can we do about displaying the results in a split? Step one is to read the psql output into a variable.
We'll replace the execute '!' ... call with
let l:results = system(l:cmd)
echo l:results
We're still echo-ing the results out like before, but now we have them in-memory before we echo to the screen. Borrowing liberally from chapter 52 of Learn Vimscript the Hard Way, let's dump our results into a new split.
function! RunSQLFile()
let l:cmd = g:sql_runner_cmd . ' -f ' . expand('%')
let l:results = systemlist(l:cmd)
" Create a split with a meaningful name
let l:name = '__SQL_Results__'
execute 'vsplit ' . l:name
" Insert the results.
call append(0, l:results)
endfunction
We changed system to systemlist to simplify our append. This is pretty straightforward: We create a buffer with a name, it gets focus automatically, and we append our results to it.
Re-open the sql file and run our mapping. It works. Now run our mapping again. Oof. It opens another split. That's a little tricky to fix (unless you've already done the extra credit in the Learn Vimscript the Hard Way chapter linked above) so we'll deal with it in a bit. In the meantime, there are two easier issues to fix:
- re-running the command will append to the content from the previous run.
- the results buffer is a "normal buffer" so Vim will prompt you to save the results if you try to delete the buffer (
bd) or close Vim. That's not ideal for a throw-away scratch buffer.
We'll make a few changes and add the following lines above the append code:
" Clear out existing content
normal! gg"_dG
" Don't prompt to save the buffer
set buftype=nofile
That's two problems solved. Now what about the unwanted additional split every time we run our command? The extra credit section in Losh's chapter gives us the hint to use bufwinnr.
If you provide bufwinnr a buffer name, it returns the number for the first window associated with the buffer or -1 if there's no match. Close and re-open Vim and we'll play with bufwinnr.
Before running our command, evaluate echo bufwinnr('__SQL_Results__') and you'll see -1. Now use the mapping on a sql file and run echo bufwinnr('__SQL_Results__') again and you'll see 1 (or a greater number if you have more splits open). If you load a different buffer in the result split window or close the results split, you'll get -1 again. What does this tell us? If we get a value other than -1, we know that our result buffer is already visible and we should re-use it rather than opening a new split. Making a few changes, our function ends up looking like this:
function! RunSQLFile()
let l:cmd = g:sql_runner_cmd . ' -f ' . expand('%')
let l:results = systemlist(l:cmd)
" Give our result buffer a meaningful name
let l:name = '__SQL_Results__'
if bufwinnr(l:name) == -1
" Open a new split
execute 'vsplit ' . l:name
else
" Focus the existing window
execute bufwinnr(l:name) . 'wincmd w'
endif
" Clear out existing content
normal! gg"_dG
" Don't prompt to save the buffer
set buftype=nofile
" Insert the results.
call append(0, l:results)
endfunction
Reload your sql file and try this a few times. It works!
Not surprisingly, using the function for awhile reveals some room for improvement. As nice as it is to iterate on sql in one Vim split and see the results quickly in the other, it is a little annoying that the results buffer gets focus. I don't want to have to jump back to the sql buffer from the results window each time. This is solved by adding execute 'wincmd p' (previous window) to the bottom of the function.
Finally, it is a bit of a pain to have to save my work before running the command each time. This is easily fixed by adding silent update to the top of the function. This will write the file if the content has changed.
For completeness, here's the final version of the plugin.
Thanks for reading. Let me know if you have any requests for future posts on Vim plugins or any feedback on this post.
That's probably enough for now, but read on if you want a quick detour and some suggested exercises.
A detour: do we need to persist the file?
Should evaluating the sql be tied to writing the file? Or is writing the file as part of evaluation an implementation detail? We could just pipe the contents of the current buffer to psql, but there's actually a good reason to evaluate the persisted file.
Consider the following SQL:
-- some comment
select 1;
-- another comment;
select true,
false,
now(; -- note the syntax error here
If you evaluate this file in psql with -f, you get the following:
$ psql hos_development -f syntax_error.sql
?column?
----------
1
(1 row)
psql:syntax_error.sql:7: ERROR: syntax error at or near ";"
LINE 3: now(;
^
Notice how it shows that the error occurred on line 7 (absolute to the file) and line 3 (relative to the problematic query). When you pipe the content in, you lose the absolute line number context.
$ cat syntax_error.sql | psql hos_development
?column?
----------
1
(1 row)
ERROR: syntax error at or near ";"
LINE 3: now(;
^
If you evaluate a file, you'll get absolute line numbers regardless of how many queries deep your syntax error occurs on. That's more important to me than avoiding some unnecessary writes.
If you really wanted to evaluate the buffer contents without saving, here's a few tips:
- As shown above,
psql can read from standard input. psql hos_development -f test.sql can be rewritten as cat test.sql | psql hos_development
- Vim's
systemlist command lets you pass a second argument to be passed along to the command as stdin
- You can get the content of the current buffer with
getline(1, '$')
That should give you enough to go on.
Suggested exercises
Add some code to allow users to skip the default mappings. You'll probably want to use a global variable like we did for g:sql_runner_cmd
Add a new mapping and function to describe the table under the cursor. I might cover this one in a future post.
