I've started making a list in my head of things I feel strongly about in software. I18n is pretty high towards the top of that list. I wrote (and re-wrote) a post explaining why i18n is so darn important, but I couldn't find a comfortable balance between all-out rant and something that felt hollow. In the meantime, I'm just going to say clearly: "Please internationalize your software."
Here's an example of I18n in the wild.
I was working on a game...
I've wanted to make a video game since I was a kid sitting at my dad's Apple IIc thumbing through the Basic manual. I briefly toyed around with various attempts over the years but never really got very serious. Last year I finally devoted some real time into learning both Unity and Phaser. I ended up shelving game-dev for a bit, but it was fun exploring new challenges.
While I was prototyping an adventure game in Phaser, I wanted to build a robust audio and text dialogue system that supported multiple language locales. I ended up finding some neat technologies and creating a comfortably streamlined workflow.
(Note that the actual mechanics of dialogue bouncing between person A and person B won't be covered here.)
Cross-browser compatible audio
Different browsers support different audio formats out of the box. If you want cross-browser compatible audio, you really want to serve your content in multiple formats. Don't fret about bandwidth: clever frameworks (Phaser included) will only download the best format for the current browser.
You want ogg for Firefox and then probably m4a and/or ac3. You might want to avoid mp3 for licensing reasons, but I'm not a lawyer (I'm also not an astronaut).
Captions in multiple languages
For our purposes, captions are really just text displayed on the screen. In nearly every adventure game, the character will encounter a locked door. Attempting to walk through that door should result in our character explaining why that can't happen yet.
Even if we didn't care about internationalization, it would make sense to refer to the caption content by a key rather than hard-coding the full text strings throughout our game. Beyond just keeping our code clean, externalizing the strings will allow us to have all our content in one place for easy editing.
Here's a very simple caption file in JSON format:
{
"found_key": "Oh, look: a key.",
"locked_door": "Drats! The door is locked.",
"entered_room": "Finally, we're indoors."
}
We'll write a function to render the caption so that we only need to pass in the key:
function say(translationKey) {
// get the text from our captions json
var textToRender = game.cache.getJSON('speechCaptions')[translationKey];
// draw our caption
game.add.text(0, 20, textToRender, captionStyle);
}
say("locked_door");
And it renders something like this:
Localizing our captions is pretty straightforward. For each language we want to support, we copy an existing translation file and replace the JSON values (not the keys) with translated versions.
We'd do well to leverage convention over configuration. Keep all captions for a locale in a folder with the locale name.
Changing locales should change the locale folder being used. Your game is always loading "captions.json" and it just decides which copy to load based on the player's locale.
Audio in multiple languages
This part doesn't need to be overly clever. Record the same content in various formats for each language.
Consider the caption JSON from the previous section. It might make sense to have one JSON file per character. With some direction, a voice actor could read each line and you could save the line with a filename matching the key (e.g. the audio "Drats! The door is locked." is saved as locked_door.wav).
We'll store the encoded versions in locale-specific folders as we did with our captions.json
And then we can update our say function to also play the corresponding bit of audio.
function say(translationKey) {
// get the text from our captions json
var textToRender = game.cache.getJSON('speechCaptions')[translationKey];
// draw our caption
game.add.text(0, 20, textToRender, captionStyle);
// speak our line
game.speech.play(translationKey);
}
say("locked_door");
Easy to create and update
Have you ever played a game or watched a movie where the captions didn't accurately reflect what was being said? This drives me crazy.
I'm guessing that the reason that audio and caption text fall out of sync is probably late content changes or the result of actors ad-libbing. Fortunately we've got a system that is friendly to rewrites from either side. Prefer the ad-lib? Update the caption file. Change the caption? Re-record the corresponding line.
The content workflow here is straightforward. To reiterate:
Create a script as json with keys and text. Edit this until you're happy. Tweak it as the game content progresses.
Translate that file into as many locales as you care about.
Losslessly record each line for each locale and save the line under the file name of the key.
Tweak captions and re-record as necessary.
That's all well and good, but now you've got a ton of raw audio files you'll need to encode over and over again. And having a user download hundreds of small audio files is hardly efficient.
We can do better. Enter the Audio Sprite. You may already be familiar with its visual counterpart the sprite sheet, which combines multiple images into a single image. An audio sprite combines multiple bits of audio into one file and has additional data to mark when each clip starts and ends.
Using the audiosprite library, we can store all of our raw audio assets in a per-locale folder and run:
➜ audiosprite raw-audio/en/*.wav -o assets/audio/en/speech
info: File added OK file=/var/folders/yw/9wvsjry92ggb9959g805_yfsvj7lg6/T/audiosprite.16278579225763679, duration=1.6600907029478458
info: Silence gap added duration=1.3399092970521542
info: File added OK file=/var/folders/yw/9wvsjry92ggb9959g805_yfsvj7lg6/T/audiosprite.6657312458846718, duration=1.8187981859410431
info: Silence gap added duration=1.1812018140589569
info: File added OK file=/var/folders/yw/9wvsjry92ggb9959g805_yfsvj7lg6/T/audiosprite.3512551293242723, duration=2.171519274376417
info: Silence gap added duration=1.8284807256235829
info: Exported ogg OK file=assets/audio/en/speech.ogg
info: Exported m4a OK file=assets/audio/en/speech.m4a
info: Exported mp3 OK file=assets/audio/en/speech.mp3
info: Exported ac3 OK file=assets/audio/en/speech.ac3
info: Exported json OK file=assets/audio/en/speech.json
info: All done
Awesome. This generated a single file that joins together all of our content and did so in multiple formats. If we peek in the generated JSON file we see
Phaser supports audiosprites quite well. We tweak our engine a bit to use sprites instead of individual files and we're good to go.
Caption display timing synchronized with audio
Now we turn to keeping the captions we're displaying in sync with the audio being played. We have all the timing data we need in our audiosprite JSON.
We'll update our say function to clean up the dialog text after the audio has ended:
function say(translationKey) {
// get the text from our captions json
var textToRender = game.cache.getJSON('speechCaptions')[translationKey];
// draw our caption
var caption = game.add.text(0, 20, textToRender, captionStyle);
// speak our line
var audio = game.speech.play(translationKey);
// set a timeout to remove the caption when the audio finishes
setTimeout(function(){
caption.destroy();
}, audio.durationMS);
}
say("locked_door");
Aside: Not everyone reads at the same speed. You'll probably want to consider having some sort of slider that acts as a multiplier for the caption duration. Readers who prefer to read more slowly can happily use 1.5X or 2X caption duration. You might not want to have the slider go less than 1X lest the captions disappear while the speech audio is still ongoing, but perhaps some portion of your audience will turn off audio in favor of reading quickly. The duration of the audio still makes sense to me as a starting point for caption duration.
The prototype code
The prototype code covers all you need to get rolling with Phaser and Audiosprites. It also has basic support for preventing people talking over each other. Hopefully you'll find it instructive or at least interesting.
That concludes this random example of I18n in the wild. Stay global, folks.
Knowing if there are any unreachable sections that have been orphaned in the writing process.
Being able to see all the branches within a book.
Knowing each branch is coherent by having an easy way to read through them.
"Never fear," I say to myself, "I can just write some code to parse the markdown files and pluck out the paths. This will be easy."
As a quick reminder, the format for a single section looks something like this:
# Something isn't right here. {#intro}
You hear a phone ringing.
- [pick up phone](#phone)
- [do not answer](#ignore-phone)
- [set yourself on fire](#fire)
(Headers specify new sections starting and have some anchor. Links direct you to new sections.)
There are plenty of ways to slurp in a story file and parse it. You could write a naive line-by-line loop that breaks it into sections based on the presence of a header and then parse the links within sections with substring matching. You could write some complicated regular expression because we all know how much fun regular expressions can become. Or you could do something saner like write a parsing expression grammar (hereafter PEG).
Why a PEG?
Generally, a regex makes for a beautiful collection of cryptic ascii art that you'll either comment-to-death or be confused by when you stumble across it weeks or months later. PEGs take a different approach and instead seek define "a formal language in terms of a set of rules for recognizing strings in the language." Because they're a set of rules, you can slowly TDD your way up from parsing a single phrase to parsing an entire document (or at least the parts you care about).
(It is worth mentioning that because the format here is pretty trivial, either the naive line-by-line solution or a regex is fine. PEGs are without a doubt the right choice IMHO for complicated grammars.)
Show me some code
We'll be using Parslet to write our PEG. Parslet provides a succinct syntax and exponentially better error messages than other competing ruby PEGs (parse_with_debug is my friend). My biggest complaint about Parslet is that the documentation was occasionally lacking, but it only slowed things down a bit - and there's an IRC channel and mailing list.
Let's start off simple, just parsing the links out of a single section of markdown. Being a TDD'er, we'll write a few simple tests first (in MiniTest::Spec):
describe LinkParser do
def parse(input)
LinkParser.new.parse(input)
end
it "can match a single link" do
parsed = parse("[some link name](#some-href)").first
assert_equal "some-href",
parsed[:id]
end
it "can match a single link surrounded by content" do
parsed = parse("
hey there [some link name](#some-href)
some content
").first
assert_equal "some-href",
parsed[:id]
end
it "can match a multiple links surrounded by content" do
parsed = parse("
hey there [some link name](#some-href)
some content with a link [another](#new-href) and [another still](#last) ok?
")
assert_equal ["some-href", "new-href", "last"],
parsed.map{|s| s[:id].to_s}
end
end
"Foul," you cry, "this is much more complicated than a regular expression!" And I reply "Yes, but it is also more intelligible long-term as you build upon it." You don't look completely satisfied, but you'll continue reading.
It is worth noting that everything has a name:
link_text encompasses everything between the two brackets in the markdown link.
link_href is the content within the parens. Because we are specifically linking only to anchors, we also include the # and then we'll name the id we're linking to via as.
link is just link_text + link_href
non_link is anything that isn't a link. It could be other markdown or plain text. It may or may not actually contain any characters at all.
content is the whole markdown content. We can see it is made up of some number of the following: non_link + link + non_link
We've specified that "content" is our root so the parser starts there.
The Scratch: Adding the 3 missing features
Now we have an easy way to extract links from sections within a story. We'll be able to leverage this to map the branches and solve all three problems.
But in order to break the larger story into sections we'll need to write a StoryParser which can parse an entire story file (for an example file, see the previous post). Again, this was TDD'ed, but we'll cut to the chase:
Now we can parse out each section's heading text, id, and content into a tree that looks something like this:
[
{:section=>{
:heading=>"Something isn't right here. "@51,
:id=>"intro"@81,
:content=>"You hear a phone ringing.\n\n- [pick up phone](#phone)..."@89}
},
{:section=>{
:heading=>"You pick up the phone... "@210,
:id=>"phone"@237,
:content=>"It is your grandmother. You die.\n\n- [start over](#intro)"@245}
},
...
]
"That's well and good," you say, "but how do we turn that into something useful?"
Enter Parslet's Transform class (and exit your remaining skepticism). Parslet::Transform takes a tree and lets you convert it into whatever you want. The following code takes a section tree from above, cleans up some whitespace, and then returns an instantiated Section class based on the input.
class SectionTransformer < Parslet::Transform
rule(section: subtree(:hash)) {
hash[:content] = hash[:content].to_s.strip
hash[:heading] = hash[:heading].to_s.strip
if hash[:id].to_s.empty?
hash.delete(:id)
else
hash[:id] = hash[:id].to_s
end
Section.new(hash)
}
end
p SectionTransformer.new.apply(tree[0])
# <Section:0x007fd6e5853298
# @content="You hear a phone ringing.\n\n- [pick up phone](#phone)\n- [do not answer](#ignore-phone)\n- [set yourself on fire](#fire)",
# @heading="Something isn't right here.",
# @id="intro",
# @links=["phone", "ignore-phone", "fire"]>
So now we have the building blocks for parsing a story into sections and then our Section class internally uses the LinkParser from above to determine where the section branches outward.
Let's finish this by encapsulating the entire story in a Story class:
class Story
attr_reader :sections
def initialize(file)
@sections = parse_file(file)
end
def branches
@_branches ||= BranchCruncher.new(@sections).traverse
end
def reachable
branches.flatten.uniq
end
def unreachable
@sections.map(&:id) - reachable
end
def split!(path)
branches.each do |branch|
File.open(path + branch.join('-') + '.md', 'w') do |f|
branch.each do |id|
section = sections.detect{|s| s.id == id}
f.puts "# #{section.heading} {##{section.id}}\n"
f.puts section.content
f.puts "\n\n"
end
end
end
end
private
def parse_file(file)
SectionTransformer.new.apply(StoryParser.new.parse(file.read))
end
end
A few notes:
You instantiate the Story class with a File object pointing to your story.
It parses out the sections
Then you can call methods to fill in the missing pieces of functionality we identified at the beginning of this post.
# Which sections are orphaned?
p story.unreachable
# => ['some-unreachable-page-id']
# What branches are there in the book?
p story.branches
# => [ ["intro", "investigate", "help"], ["intro", "investigate", "rescue", "wake-up"], ["intro", "investigate", "grounded"], ["intro", "grounded"] ]
# Let me read each narrative branch by splitting each branch into files
story.split!('/tmp/')
# creates files in /tmp/ folder named for each section in a branch
# e.g. intro-investigate-help.md
# You can read through each branch and ensure you've maintained a cohesive narrative.
If you made it this far, you deserve a cookie and my undying affection. I'm all out of cookies and any I had would be gluten-free anyway, so how about I just link you to the example code instead and we call it even?
Remember Choose Your Own Adventure books? I fondly remember finding new ways to get myself killed as I explored Aztec ruins or fought off aliens. Death or adventure waited just a few pages away and I was the one calling all the shots.
Introducing my son to Hypertext Fiction has rekindled my interest. I wondered how difficult it would be to throw something together to let me easily write CYOA-style books my kid could read on a kindle. I love markdown, so a toolchain built around it was definitely in order.
As it turns out, Pandoc fits the bill perfectly. You can write a story in markdown and easily export it to EPUB. From there you're just a quick step through ebook-convert (via calibre's commandline tools) to a well-formed .mobi file that reads beautifully on a kindle.
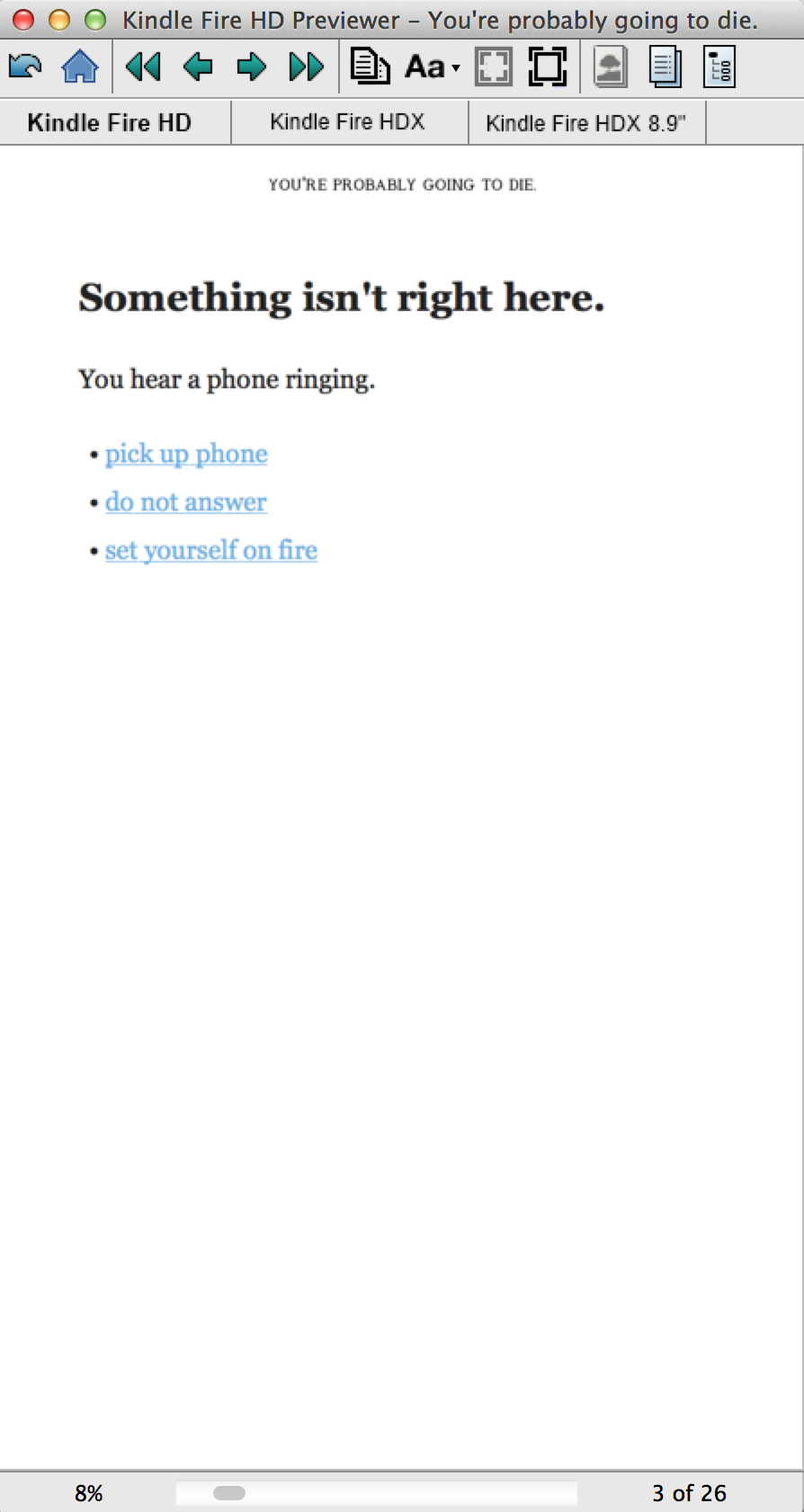
Here's a quick example markdown story:
% You're probably going to die.
% Jeffrey Chupp
# Something isn't right here. {#intro}
You hear a phone ringing.
- [pick up phone](#phone)
- [do not answer](#ignore-phone)
- [set yourself on fire](#fire)
# You pick up the phone... {#phone}
It is your grandmother. You die.
- [start over](#intro)
# You ignore the phone... {#ignore-phone}
It was your grandmother. You die.
- [start over](#intro)
# You set yourself on fire... {#fire}
Strangely, you don't die. Guess you better start getting ready for school.
- [pick up backpack and head out](#backpack)
- [decide to skip school](#skip)
# You decide to skip school {#skip}
A wild herd of dinosaurs bust in and kill you. Guess you'll never get to tell your friends about how you're immune to flame... or that you met live dinosaurs :(
- [start over](#intro)
# Going to school {#backpack}
You're on your way to school when a meteor lands on you, killing you instantly.
- [start over](#intro)
From the top, we have percent signs before the title and author which Pandoc uses for the title page.
Then each chapter/section begins with an h1 header which has an id specified. This id is what we'll use in our links to let a reader choose where to go next.
If you don't specify a link, Pandoc will dasherize your header text, but it is probably easier to be specific since you need to reference it in your link choices anyway.
Save that as story.md and run the following to get your epub and mobi versions: