Quick and Dirty OCR for Letterpress & Other Tile-based Games
I've been playing enough Letterpress lately to realize that I'm not great at it. This is super frustrating for me when this is a game that you could easily teach a computer to play.
I'm not the first person to have that thought. There are plenty of cheating programs for Letterpress (just google or search in the app store).
I haven't investigated these solvers but in thinking about the problem, the basic approach would seem to be:
- Take screenshot of game and import it into solver
- Parse the board into a string of letters
- Reduce a dictionary of valid words against those characters to find playable words
- Optionally make recommendations of which word to play based on current board state and strategy.
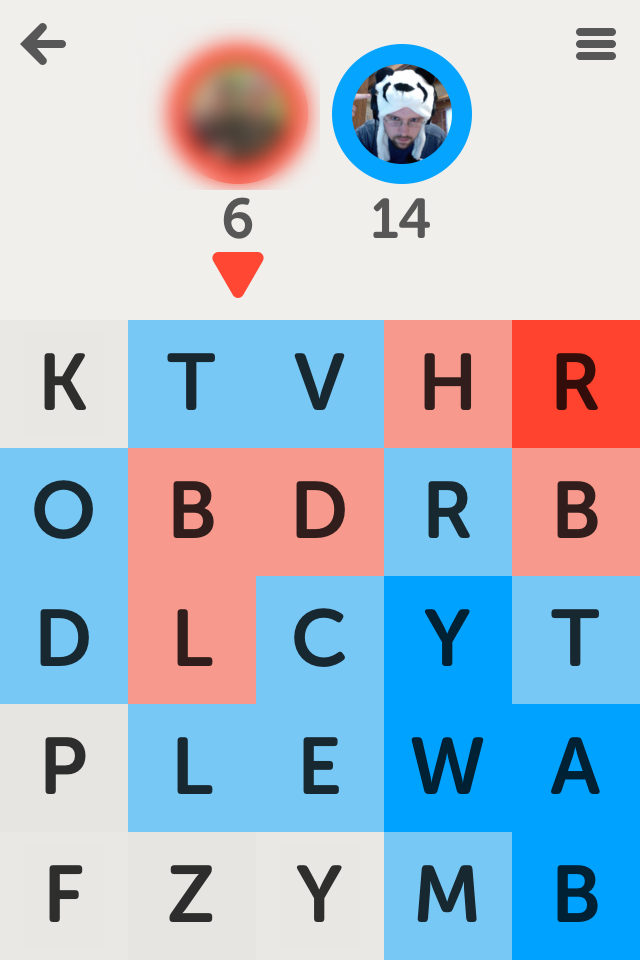
I wondered how quickly I could throw something together to simply parse the game board into a string of letters. It turns out it is super easy. To get started I took a screenshot of a game in progress and downloaded it from my phone.
I'd heard about tesseract back when it was first announced and it seemed worth giving it a shot. I started with brew install tesseract and tried simply passing in the board image unmodified:
$ tesseract light.png /tmp/output
$ cat /tmp/output.txt
R
QM V
66:
KONot even close. The homebrew instructions recommend grayscaling the image first with ImageMagick, so what do we get after that?
$ convert light.png -type Grayscale /tmp/gray.tif
$ tesseract /tmp/gray.tif /tmp/output
$ cat /tmp/output.txt
QM
V
w
A‘ K
6'Ugh, even worse.1
But poking through tesseract's options reveal some promise via pagesegmode settings:
7 = Treat the image as a single text line.and
10 = Treat the image as a single character.7 turned out to be a bust, but after testing option 10 on a few individual tiles, things were starting to look up. So let's break the image up into the individual 25 tiles and recognize each one.
There may be more elegant ways to break the image into tiles, but I ended up using two ImageMagick commands:
# remove the non-tile content (i.e. the scores, etc. in the header)
convert light.png -gravity North -chop 0x320 /tmp/headless.png
# break the tile-content into 128x128px chunks
convert /tmp/headless.png -crop 128x128 /tmp/tile_%02d.pngThen I wrapped these two commands up in a ruby class for ease of use and wrote a simple test.
so, running the ruby class:
$ ruby -r ./board_parser -e "puts BoardParser.new('light.png').tiles.join"
KTVHROBDRBDLCYTPLEWAFZYMBBingo! A perfect match, ready to be compared to a dictionary of valid words.
It turns out tesseract is great at matching single tiles regardless of color scheme or captured state of the tile. The tests for the code run against screenshots from all available color schemes.
This approach is dead-simple and leans heavily on solid existing technologies. Because of this, the glue code itself doesn't have to be clever at all :)
Note that this quick hack is only designed to work against iPhone 4 resolution screenshots -you would have to (at least) change the header crop size for iPhone 5.
1: The recommendation to convert the image to grayscale is a good hint that tesseract probably relies a lot on consistent contrast. This coupled with the fact that we're dealing with random letters instead of words definitely stacks the cards against tesseract. Dealing with individual tiles/characters solves both the confusion of multiple contrasts and the confusion of dealing with random gibberish.
